本帖最后由 Demon 于 2012-7-25 20:14 编辑
标题: 批处理技术内幕:批处理与Unicode
作者: Demon
链接: http://demon.tw/reverse/cmd-internal-unicode.html
版权: 本博客的所有文章,都遵守“署名-非商业性使用-相同方式共享 2.5 中国大陆”协议条款。
CMD在内部是以Unicode来运作的,这点无须置疑。你可能要问,如果是Unicode的话,那么Unicode编码保存的脚本怎么不能执行?
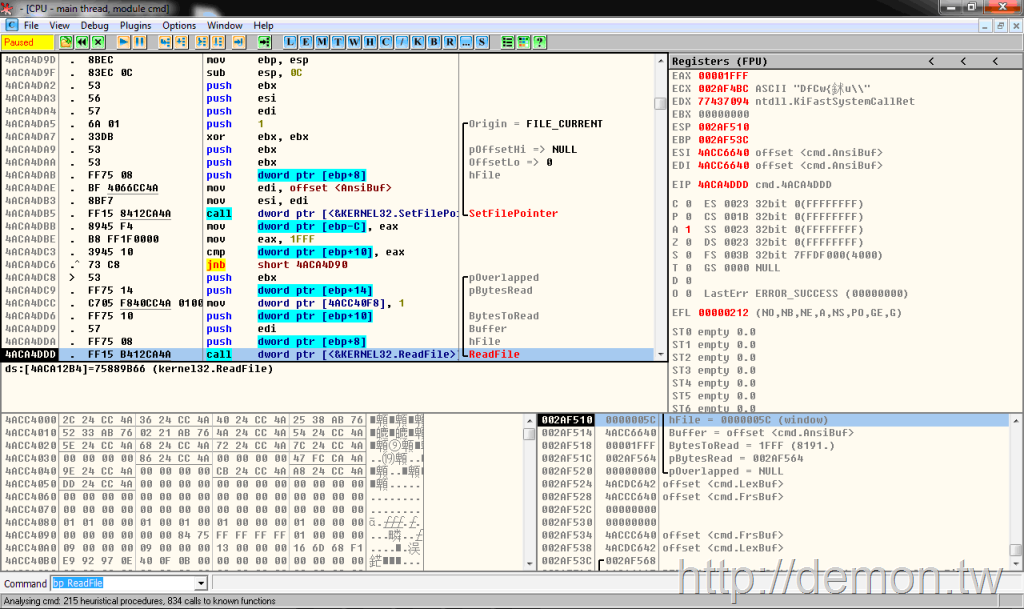
让我们一起来看一下CMD是怎么解析批处理脚本的吧。复制代码 用OllyDbg载入,bp ReadFile后运行,就会断在读取脚本的地方。
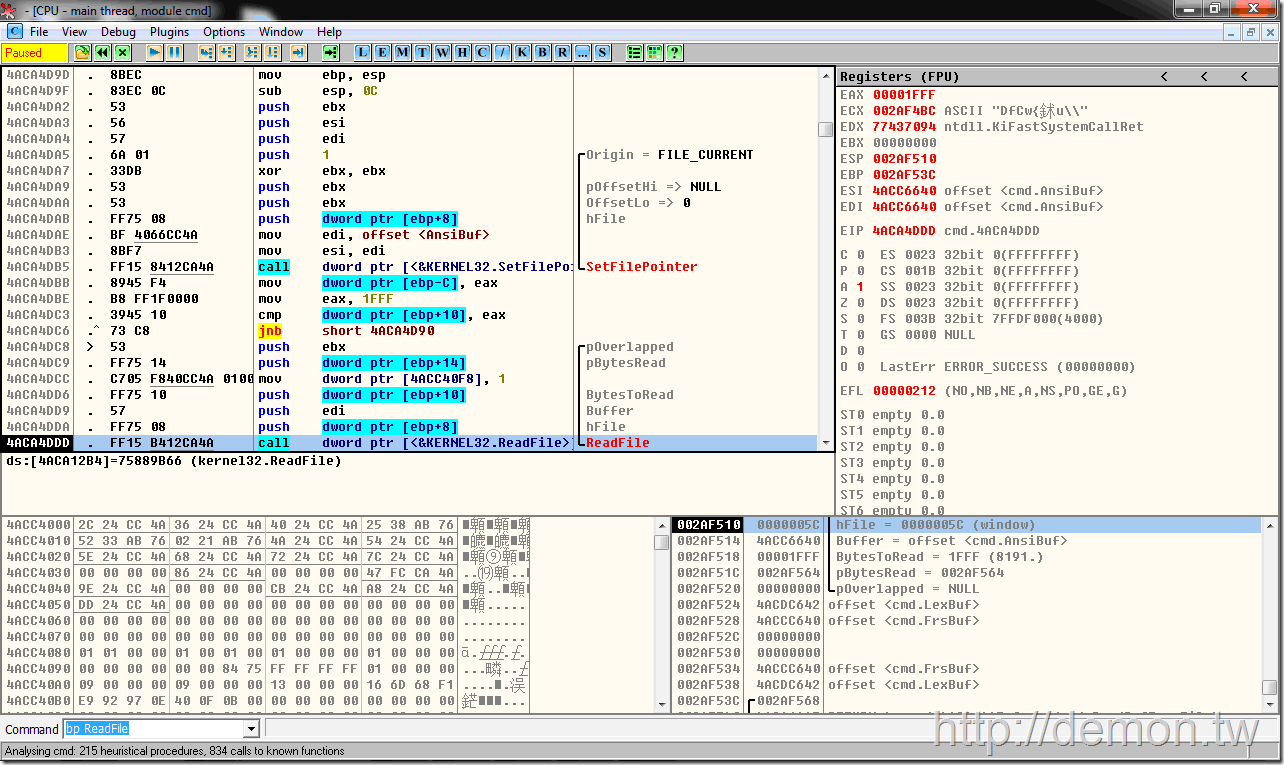
可以看到每次读取0x1FFF(8191)个字节(注意不是字符)到缓冲区。
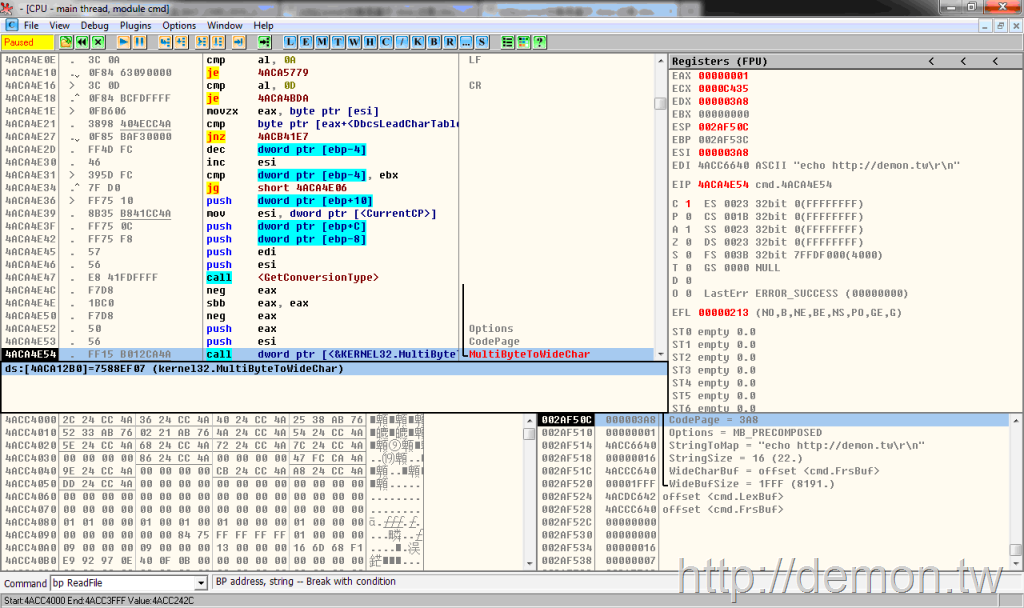
F8单步,不一会就到了MultiByteToWideChar函数,将刚才读取的字节以当前代码页转换成Unicode储存在另一个缓冲区,之后的处理都是建立在转换后的Unicode之上的。
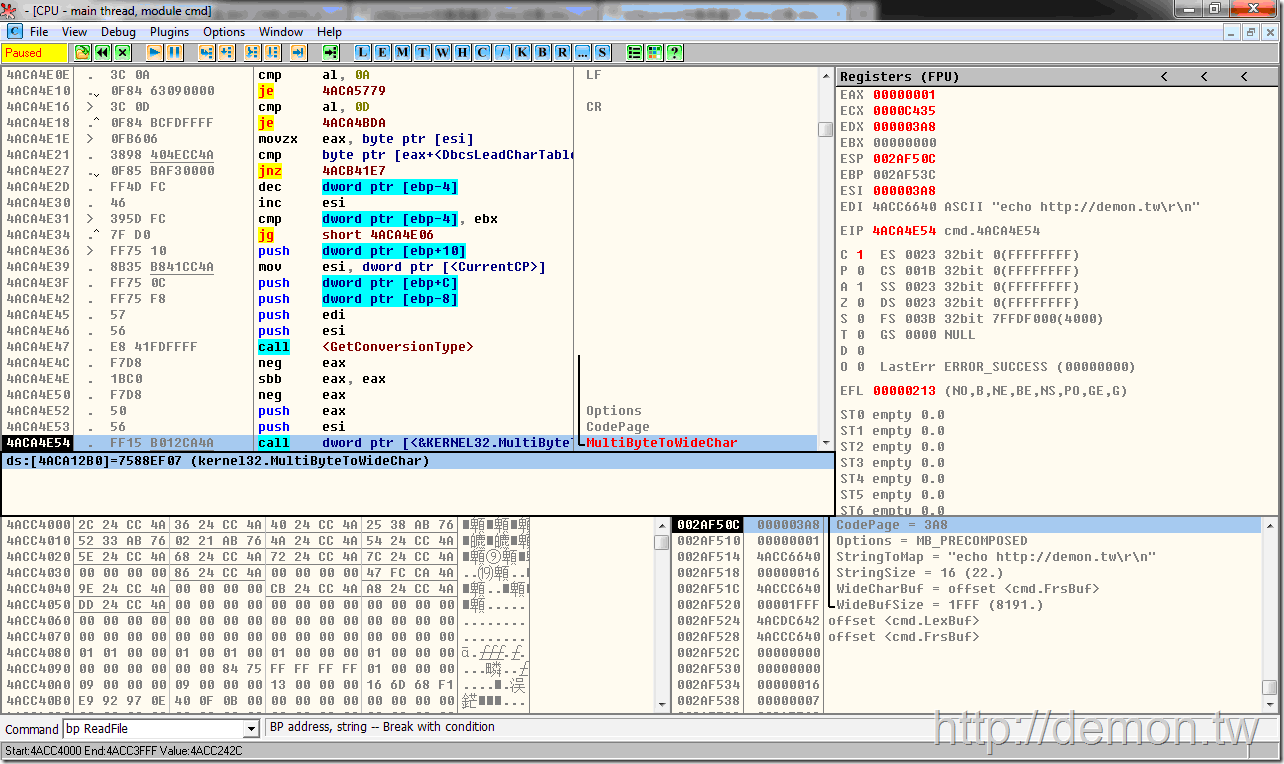
也就是说,CMD在读取脚本时并不会预先判断脚本的编码(实际上,要准确判断文件编码几乎是不可能的),而是调用ReadFile函数读取文件后以当前代码页调用MultiByteToWideChar函数将其转成Unicode编码。如果你的是简体中文系统,而你没有修改默认的区域设置,并且你没有在批处理中使用chcp命令的话,那么默认的当前代码页就是936,即GBK编码。
就算你的批处理是使用Unicode保存的,CMD也不会知道,CMD仍然傻傻的把它当成GBK,Unicode被当成GBK转换成Unicode,结果当然是不能运行的。
到这里还没有结束,我们都知道CMD有一个/U开关,帮助文档对/U的描述是:- Causes the output of internal commands to a pipe or file to be Unicode
对应的还有一个/A开关:- Causes the output of internal commands to a pipe or file to be ANSI
默认是开关是/A,也就是说CMD命令输出的默认编码是ANSI。
等一下,好像哪里不对吧?是的,只有在输出被重定向到管道或者文件的时候才是ANSI(默认,不加/U的话),换句话说,如果直接在CMD输出,那么仍然是Unicode编码。- echo 你好,世界
- echo 你好,世界>1.txt
CMD对这两行代码的处理是不一样的。
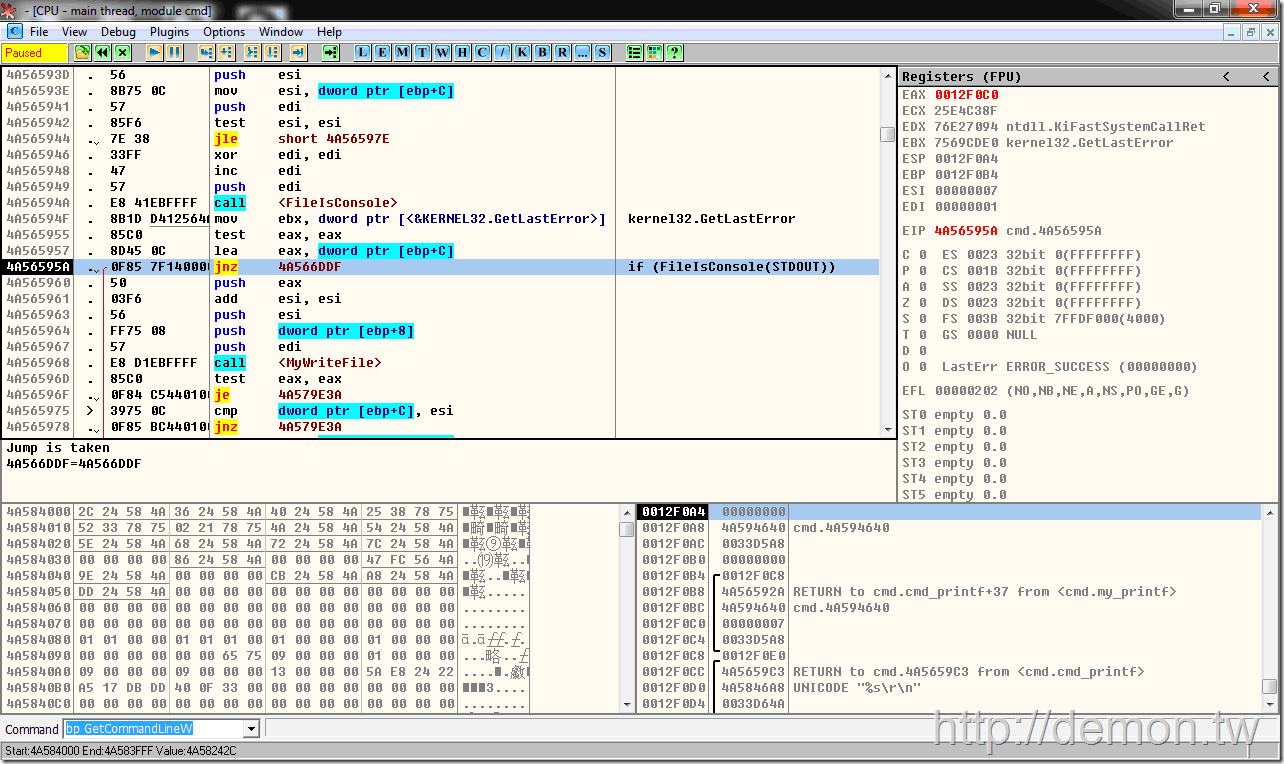
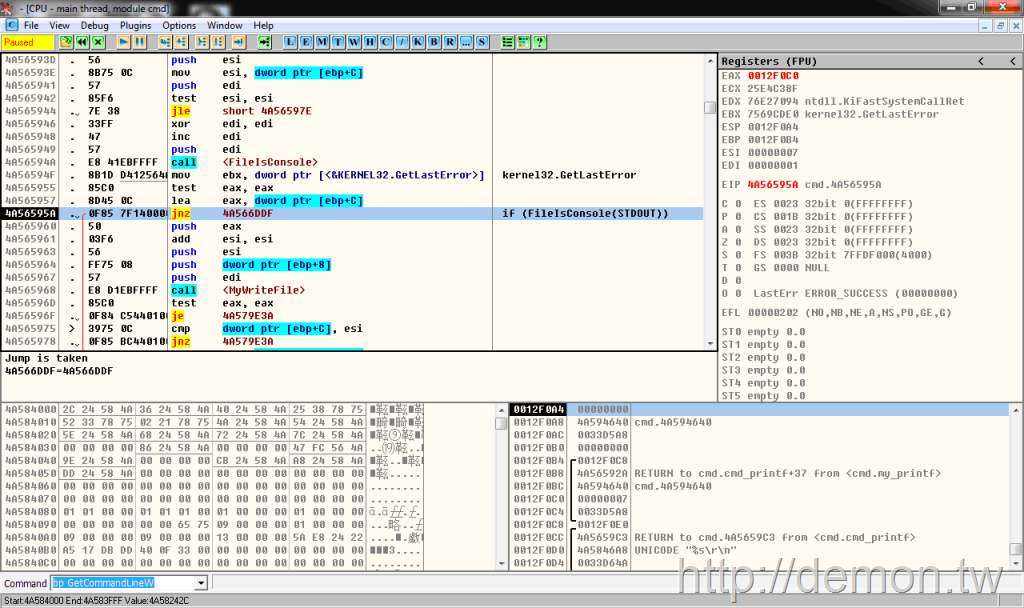
如果标准输出STDOUT没有被重定向(第一行代码),那么直接调用WriteConsoleW函数输出Unicode。
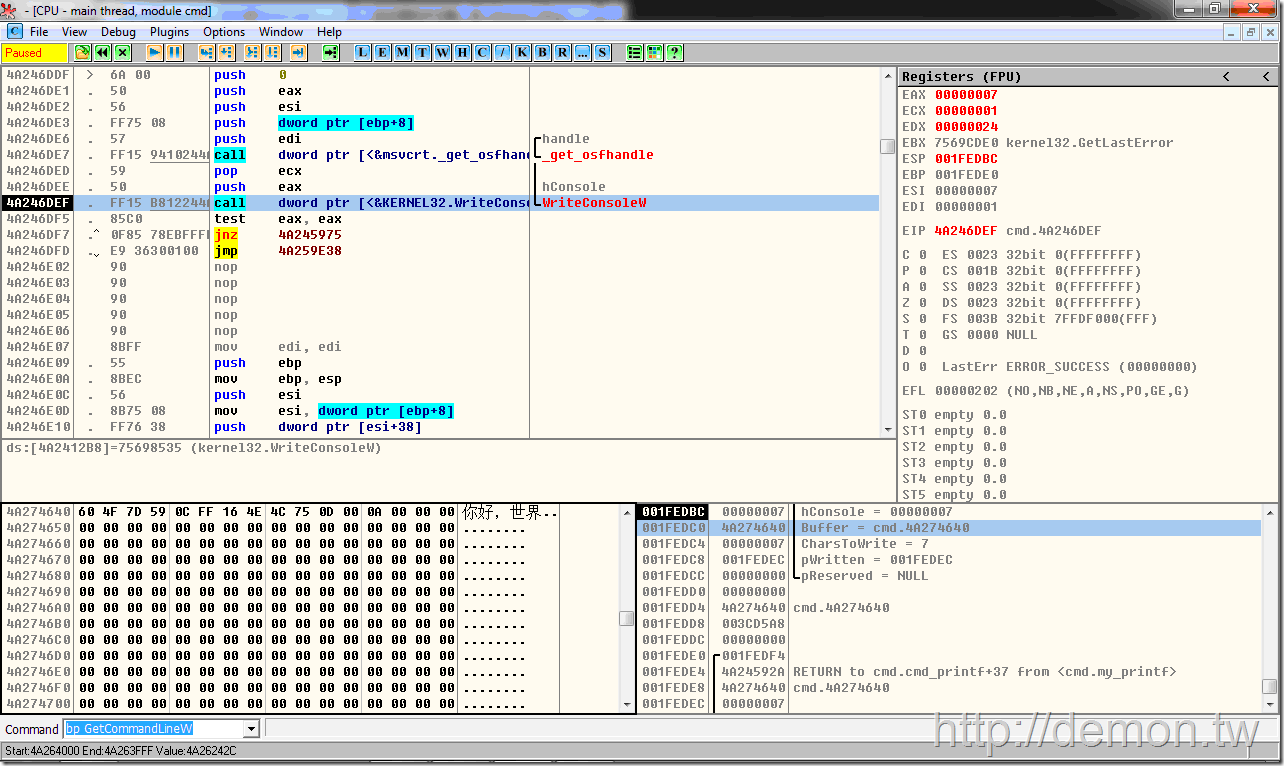
如果标准输出STDOUT被重定向了(第二行代码),那么会先以当前代码页为参数调用WideCharToMultiByte函数将Unicode转成相应的编码,再调用WriteFile写入文件。
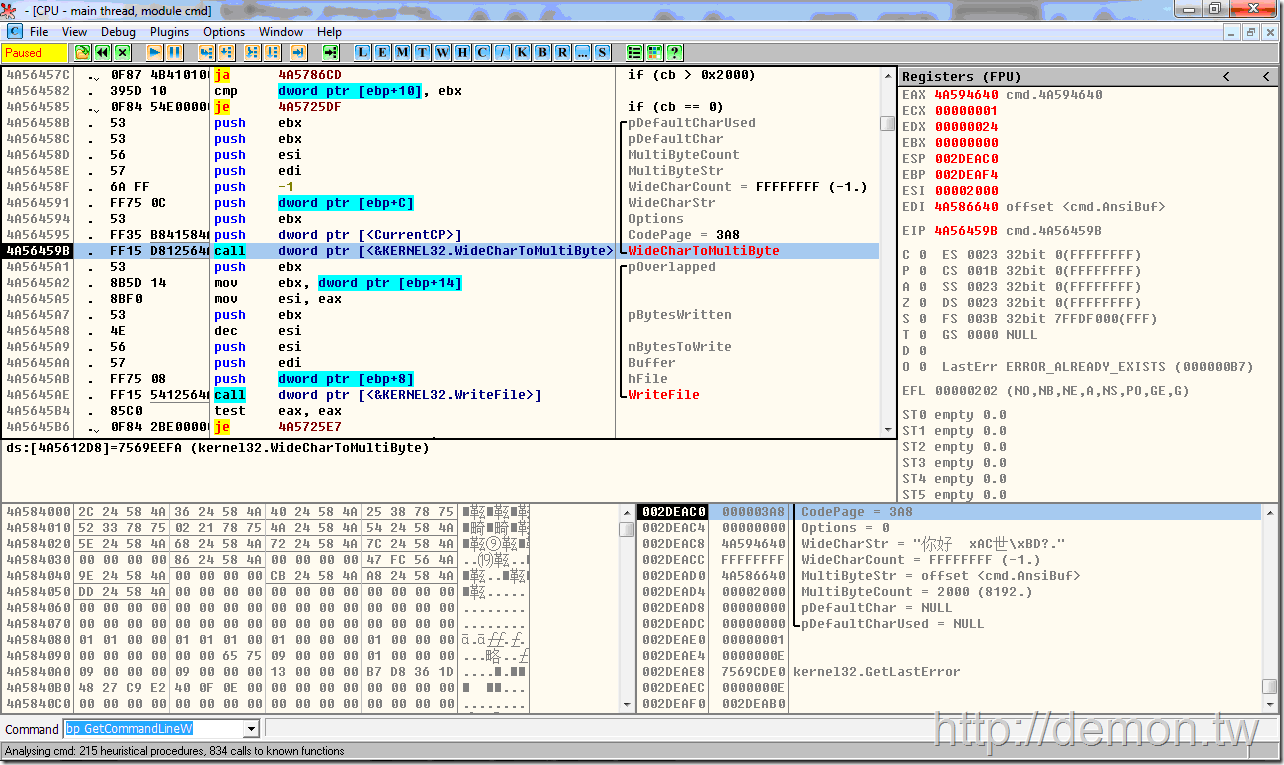
请注意我一直强调当前代码页,因为代码页是可以通过chcp命令改变的,所以从MultiByteToWideChar到WideCharToMultiByte这段时间里,当前的代码页很可能被改变了。
猜猜看下面这段批处理会输出什么?- @echo off
- setlocal enabledelayedexpansion
- chcp 437>nul
- set c=個
- chcp 1252>nul
- echo !c!>1.txt
- pause
为了减低难度,给出两个链接:
http://en.wikipedia.org/wiki/Code_page_437
http://en.wikipedia.org/wiki/Windows-1252
如果你不用运行就能知道答案,那么恭喜你已经理解本文了;如果你就算实际运行了还是想不明白为什么,那也不用灰心,我会告诉你答案。
前两行大家都懂,我就不说了,第三行chcp将当前活动的代码页改为437,CMD就会把之后的代码当成437编码(请允许我这么称呼,因为我实在不知道它叫什么编码)。
好在437编码是部分兼容ASCII的,所以"set c="并不会有什么问题,它仍然是"set c=";但是437里面是没有"個"这个中文字符的,它会把"個"当成0×82和0×80两个字符,而437中的0×82和0×80对应Unicode中的0x00E9和0x00C7(上面的链接里有映射表),于是复制代码 这行代码运行之后c在内存中的值是0x00E9 0x00C7。
接下来chcp将代码页改成了1252,而下一行echo是把c的值重定向输出到1.txt,所以要把Unicode转成1252编码。0x00E9对应1252中的0xE9,0x00C7对应1252中的0xC7(参考上面的链接),所以转换以后的值是0xE9 0xC7,即1.txt的内容为0xE9 0xC7(当然,还有echo附加上去的0x0D 0x0A)。
用记事本打开1.txt时当前的代码页仍然是936不变,所以将按照GBK编码来解释0xE9 0xC7,这正好是"榍"字的GBK码,怎么样,是不是绕晕了?
如果你还是搞不明白,那也没关系,你只要知道CMD会先把批处理脚本转成Unicode再进行解析的就行了;如果你搞懂了,那可以考虑一下下面的代码会生成什么:复制代码 可以参考http://en.wikipedia.org/wiki/EBCDIC_037 | 




 发表于 2012-7-25 19:52
|
发表于 2012-7-25 19:52
| 

 发表于 2012-7-26 13:27
|
发表于 2012-7-26 13:27
| 