
标题: [文本处理] 【已解决】批处理怎样读取字符串替换另外一个TXT文本中对应的字符串? [打印本页]
作者: TXTUSER 时间: 2024-10-31 21:11 标题: 【已解决】批处理怎样读取字符串替换另外一个TXT文本中对应的字符串?
本帖最后由 TXTUSER 于 2024-11-12 10:52 编辑
从《字典》TXT文本中读取字符串替换《原文》TXT文本中对应的字符串;
字典TXT
A=SIN(Y)
B=LOG(100)
C=TAN(Z)
D=COS(X)
以下N行省略...
原文TXT
AD=MAX(A,B)+MAX(C,D)
.....以下N行省略
结果的例子
AD=MAX(SIN(Y),LOG(100))+MAX(TAN(Z),COS(X))
作者: aloha20200628 时间: 2024-10-31 22:43
本帖最后由 aloha20200628 于 2024-11-1 15:10 编辑
回复 1# TXTUSER
匹配范围》原文.txt 每行可能出现的两种类型函数表达式中的一种,如下示例:
AD=MAX(A,B)+MAX(C,D)
XY=MIN(A,C)- @echo off &setlocal enabledelayedexpansion
- (for /f "tokens=1-6 delims=(,)" %%a in (
- 'findstr /i "([a-z][a-z]*,[a-z][a-z]*)" 《原文》.txt') do (
- set "s=%%a(_%%b,_%%c)" &if "%%d" neq "" set "s=!s!%%d(_%%e,_%%f)"
- for /f "tokens=1-2 delims==" %%x in (
- 'findstr /i "%%b= %%c= %%e= %%f=" 《字典》.txt') do set "s=!s:_%%x=%%y!"
- echo,!s!
- ))>"《原文》.new.txt" 2>nul
- type "《原文》.new.txt"
- endlocal&pause&exit/b
作者: TXTUSER 时间: 2024-10-31 23:44
回复 TXTUSER
匹配范围》原文.txt 每行可能出现的两种类型函数表达式中的一种,如下示例:
AD= ...
aloha20200628 发表于 2024-10-31 22:43 
原文不是单一的一行,有很多行算式
AD=MAX(A,B)+MAX(C,D)
SU=DC(OE+FC)
HI=SUM(A*OE)
文本内容很多,每行都是一个算式
字典业有很多条
A=SIN(Y)
B=LOG(100)
C=TAN(Z)
D=COS(X)
OE=POW(3)
FC=SQRT(6)
以下N行省略...
请老师再优化一下
作者: qixiaobin0715 时间: 2024-11-1 09:19
本帖最后由 qixiaobin0715 于 2024-11-1 09:30 编辑
回复 1# TXTUSER
你把原文txt放到网盘上,让大家帮你参谋参谋。
举例示范规律性不强,你自己又没说清楚。
作者: TXTUSER 时间: 2024-11-1 10:24
回复 4# qixiaobin0715 提示
附件上传不成功
作者: qixiaobin0715 时间: 2024-11-1 10:41
回复 5# TXTUSER
本论坛关闭了附件上传功能,我说的是网盘
作者: aloha20200628 时间: 2024-11-1 11:08
本帖最后由 aloha20200628 于 2024-11-1 15:17 编辑
回复 3# TXTUSER
二楼代码已订正如下,可以匹配3楼的示例样本了,目前设定可匹配1-4个圆括号运算项,设定每个运算项内可匹配1-2个变量...
- @echo off &setlocal enabledelayedexpansion
- (for /f "delims=" %%s in (《原文》.txt) do (
- set "s=%%s"
- for /f "tokens=1-8 delims=()" %%a in ("%%s") do (
- for %%i in ("%%b" "%%d" "%%f" "%%h") do (
- for /f "tokens=1-2 delims=,+-/*" %%1 in ("%%~i") do (
- set "v=%%1=" &if "%%2" neq "" set "v=!v! %%2="
- for /f "tokens=1-2 delims==" %%x in (
- 'findstr /i "!v!" 《字典》.txt'
- ) do set "s=!s:(%%x=(%%y!" &set "s=!s:%%x)=%%y)!")
- ))
- if "%%s" neq "!s!" echo,!s!
- ))>"《原文》.new.txt" 2>nul
- type "《原文》.new.txt"
- endlocal&pause&exit/b
作者: Batcher 时间: 2024-11-1 12:50
回复 5# TXTUSER
如果需要上传文件,请用使用网盘。例如:
百度:https://pan.baidu.com
蓝奏:https://www.lanzou.com
如果需要上传截图,可以找个图床,例如:
http://bbs.bathome.net/thread-60985-1-1.html
作者: idwma 时间: 2024-11-1 14:33
ps也来试一下- #@&cls&powershell "type '%~0'|out-string|iex"&pause&exit
- $aaaa='字典.txt'
- $bbbb='原文.txt'
- gc $aaaa|%{$cccc=$_ -split '=';iex('$'+$cccc[0]+'="'+$cccc[1]+'"')}
- (gc $bbbb)|%{
- [regex]::replace(
- $_,
- '(?<=\()[^)]+(?=\))',
- {
- [regex]::replace(
- $args[0].groups[0]-join'',
- '\w+',
- {iex('$'+$args[0].groups[0])}
- )
- }
- )
- }|sc $bbbb
作者: Five66 时间: 2024-11-1 16:53
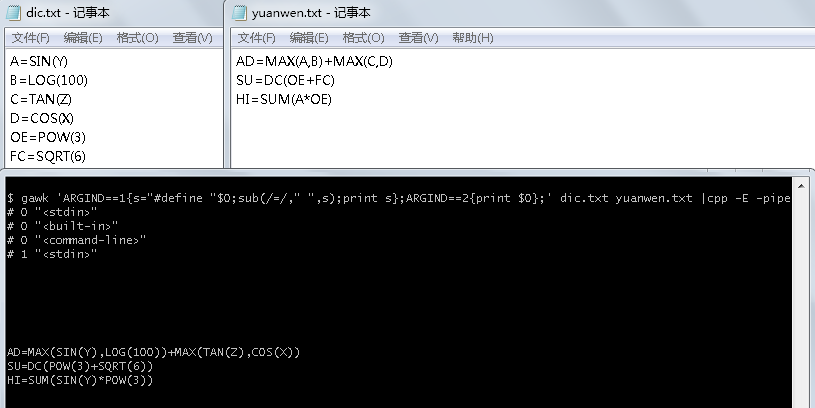
啊 ,这要想准确 ,应该得像编译器或解析器那样对原文件进行分词(Tokenization)吧 ,自己弄挺麻烦的 ,可以弄成C宏或m4宏 ,然后用对应的宏处理器进行替换
比如下面的 ,在mingw里用gawk将字典dic.txt替换换成C宏 ,然后用C宏处理程序对原文件yuanwen.txt进行处理的输出结果
作者: TXTUSER 时间: 2024-11-5 23:32
回复 TXTUSER
二楼代码已订正如下,可以匹配3楼的示例样本了,目前设定可匹配1-4个圆括号运算项,设定 ...
aloha20200628 发表于 2024-11-1 11:08
烦请老师参见附件优化一下例子
作者: TXTUSER 时间: 2024-11-5 23:33
本帖最后由 TXTUSER 于 2024-11-8 13:00 编辑
回复 9# idwma
烦请老师参见附件优化一下
作者: TXTUSER 时间: 2024-11-5 23:36
回复 8# Batcher
发了网盘链接,怎么不显示啊
作者: TXTUSER 时间: 2024-11-5 23:37
本帖最后由 TXTUSER 于 2024-11-8 13:01 编辑
回复 7# aloha20200628
烦请老师参见附件优化一下
作者: qixiaobin0715 时间: 2024-11-6 08:56
本帖最后由 qixiaobin0715 于 2024-11-6 08:57 编辑
使用代码完成某个项目的处理时,需要比较清晰的逻辑为基础。根据顶楼的描述,替换字符串存在于字典文件中。楼主提供的网盘文件又有不同,替换字符串同时存在于字典文件和原文文本中,关键是代码如何判定原文文件中的字符串,哪个是需要替换的字符串,哪个又是要被替换的字符串?
作者: qixiaobin0715 时间: 2024-11-6 09:04
4楼提的要求等于没说,我的本意是在网盘 上传真实的需要处理的文件,而不是随意杜撰一些文件。
作者: TXTUSER 时间: 2024-11-6 10:15
回复 15# qixiaobin0715
字典中的X\Y分别对应原文中的数组变量
作者: TXTUSER 时间: 2024-11-6 10:16
回复 16# qixiaobin0715
附件中的结果就是真实的需要
作者: qixiaobin0715 时间: 2024-11-6 10:26
回复 17# TXTUSER
原文中的P1是怎么回事呢?
作者: TXTUSER 时间: 2024-11-6 11:22
本帖最后由 TXTUSER 于 2024-11-8 13:01 编辑
回复 19# qixiaobin0715
老师,我重新传了附件,
这次简化了一下
请帮助解决
作者: qixiaobin0715 时间: 2024-11-6 11:36
本帖最后由 qixiaobin0715 于 2024-11-6 14:44 编辑
原来是股票啊,真搞不懂这些函数的关系。你这就不是单纯的替换了。
作者: idwma 时间: 2024-11-6 18:53
本帖最后由 idwma 于 2024-11-6 19:02 编辑
原文有两行为什么结果只留一行- #@&cls&powershell "type '%~0'|out-string|iex"&pause&exit
- $aaaa='字典.txt'
- $bbbb='原文.txt'
- $dddd='结果.txt'
- $eeee=gc $bbbb
- gc $aaaa|%{$cccc=$_ -split '=';$eeee=$eeee -replace $cccc[0],$cccc[1]}
- sc $dddd $eeee
作者: TXTUSER 时间: 2024-11-7 10:33
回复 22# idwma
结果和原文一样的,没有替换成功
作者: qixiaobin0715 时间: 2024-11-7 10:59
20楼附件处理后 DLL1(17,SIGNALS_USER(4567,2),0,0)
17、0、0这3个数是如何得到的?
作者: idwma 时间: 2024-11-7 11:02
回复 23# TXTUSER
你举的例子和实际数据不一样,很难帮到你啊
作者: qixiaobin0715 时间: 2024-11-7 15:46
好像有点看明白了,多层嵌套式参数替换,使用批处理应当不适合,最好想想其它方法。
作者: aloha20200628 时间: 2024-11-7 15:50
本帖最后由 aloha20200628 于 2024-11-7 15:52 编辑
楼主后来提供的示例文件和要求,与开始定义的原文/字典规则出现了冲突,并加入了函数表达式整体置换的要求,如此,原文不是纯粹的原文,字典不是纯粹的字典,而且依据变量替换的顺序或依据函数表达式整体替换的顺序会导出不同的结果
作者: idwma 时间: 2024-11-8 08:57
本帖最后由 idwma 于 2024-11-8 09:06 编辑
最后一个链接失效了,只测了前面的
变量名随便输的,如果和文件里的有冲突还要改一下- #@&cls&powershell "type '%~0'|out-string|iex"&pause&exit
- $aaaa='字典.txt'
- $bbbb='原文.txt'
- $dddd='结果.txt'
- gc $aaaa|?{$_ -match '='}|%{$cccc=$_ -split '=';iex('$'+$cccc[0]+'="'+$cccc[1]+'"')}
- $table=@{}
- gc $bbbb|?{$_ -match '='}|%{
- $s=$_.trim()
- while(
- [regex]::matches($s,"\w+(?=(\((?:[^()]+|(?<Open>)\(|(?<-Open>)\))+(?(Open)(?!))\)))")|%{
- $i=$_.groups[0].value+$_.groups[1].value
- $table[$_.groups[0].value]=$_.groups[0].value+$_.groups[1].value
- if($i -match '^\w+\([^)]+\)$'){
- $s=$s -replace [regex]::Escape($i),('$table["{0}"]' -f $_.groups[0].value)
- }
- 1
- }
- ){}
-
- while(
- [regex]::matches($s,'\$\w+\[\"([^]]+)\"\]')|%{
- $g=iex "$_"
- $i=iex('$'+$_.groups[1])
- if($i -ne $null){
- $k=$g -split '[(,)]'
- $table['c']=1
- $j=[regex]::replace(
- $i,
- '(?<=[(,])[A-Z]\w*(?=[,)])',
- {$k[$table['c']++]}
- )
- $s=$s -replace [regex]::Escape("$_"),$j
- 1
- }else{
- $s=$s -replace [regex]::Escape("$_"),$g
- 1
- }
- }
- ){}
-
- $cccc=$s -split '='
- iex('$'+$cccc[0]+'="'+$cccc[1]+'"')
-
- [regex]::replace(
- $s,
- '(?<=[(,])\w+(?=[,)])',
- {
- $a=$args[0].groups[0]
- if(test-path('Variable:'+$a)){iex('$'+$a)}else{$a}
- }
- )
- }|sc $dddd
作者: TXTUSER 时间: 2024-11-8 12:34
回复 26# qixiaobin0715
写成dll也行,麻烦老师了
作者: TXTUSER 时间: 2024-11-8 12:58
回复 28# idwma
感谢老师支持,完美解决!
作者: TXTUSER 时间: 2024-11-8 13:25
回复 28# idwma
追问老师一下,遇到下面的问题报错,如何处理?
原文增加了一行JJ=H+2 ,字典里面的H=TDXDLL1(4,0,1,0),+=TDXDLL1(35,X,Y,0)
运行后报错
$+=TDXDLL1(35,X,Y,0) : 无法将“$+=TDXDLL1(35,X,Y,0) ”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名
称的拼写,如果包括路径,请确保路径正确,然后再试一次。
所在位置 行:1 字符: 1
+ $+="TDXDLL1(35,X,Y,0) "
+ ~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : ObjectNotFound: ($+=TDXDLL1(35,X,Y,0) :String) [], CommandNotFoundException
+ FullyQualifiedErrorId : CommandNotFoundException
作者: idwma 时间: 2024-11-9 21:56
应该可以了,有错再改- #@&cls&powershell "type '%~0'|out-string|iex"&pause&exit
- $aaaa='字典.txt'
- $bbbb='原文.txt'
- $dddd='结果.txt'
- $elbat=@{}
- gc $aaaa|?{$_ -match '='}|%{$cccc=$_ -split '(?<=^[^=]+)=';$elbat[$cccc[0]]=$cccc[1]}
- $table=@{}
- gc $bbbb|?{$_ -match '='}|%{
- $s=$_.trim()
- $table['thisway']=0
- while(
- [regex]::matches($s,"\w+(?=(\((?:[^()]+|(?<Open>)\(|(?<-Open>)\))+(?(Open)(?!))\)))")|%{
- $i=$_.groups[0].value+$_.groups[1].value
- $j=$_.groups[0].value+($table['thisway']++)
- $table[$j]=$_.groups[0].value+$_.groups[1].value
- if($i -match '^\w+\([^)]+\)$'){
- $s=$s -replace [regex]::Escape($i),('$table["{0}"]' -f $j)
- }
- 1
- }
- ){}
-
- while(
- [regex]::matches($s,'\$\w+\[\"([^]]+)\"\]')|%{
- $g=iex "$_"
- $i=iex('$'+$_.groups[1])
- if($i -ne $null){
- $k=$g -split '[(,)]'
- $table['thisway']=1
- $j=[regex]::replace(
- $i,
- '(?<=[(,])[A-Z]\w*(?=[,)])',
- {$k[$table['thisway']++]}
- )
- $s=$s -replace [regex]::Escape("$_"),$j
- 1
- }else{
- $s=$s -replace [regex]::Escape("$_"),$g
- 1
- }
- }
- ){}
-
- $cccc=$s -split '(?<=^[^=]+)='
- $elbat[$cccc[0]]=$cccc[1]
-
- [regex]::replace(
- $s,
- '(?<=[(,+=])\w+(?=[,)+=])',
- {
- $a=$args[0].groups[0].value
- if($elbat[$a] -ne $null){$elbat[$a]}else{$a}
- }
- )
- }|sc $dddd
作者: TXTUSER 时间: 2024-11-10 13:42
回复 32# idwma
老师好,经多次测试报告如下:① 没有出现报错情况,②但是出来的结果和28楼不一致,③+号也没有被替换,请老师有空再修改一下,谢谢。
另外汉字没有被识别,乱码,改为拼音就好了
作者: idwma 时间: 2024-11-10 14:50
JJ=TDXDLL1(4,0,1,0)+2
AD=MAX(TAN(Z),COS(X))+MAX(TAN(Z),COS(X))
替换了+号应该是什么样的
作者: TXTUSER 时间: 2024-11-10 17:59
回复 34# idwma 替换规则和之前的事一样的,X,Y两个变量分别被替换为+号左右两边的字符串,具体结果如下:
JJ=TDXDLL1(35,TDXDLL1(4,0,1,0),2,0)
AD=TDXDLL1(35,MAX(TAN(Z),COS(X)),MAX(TAN(Z),COS(X)),0)
作者: idwma 时间: 2024-11-11 00:39
乱码文件编码另存为ANSI看看
只测了这些
原文
P1=SIGNALS_USER(4567,2)
P2=REF(H,BARSLAST(P1))
JJ=H+2
AD=MAX(A,B)+MAX(C,D)
字典
H=TDXDLL1(4,0,1,0)
+=TDXDLL1(35,X,Y,0)
REF=TDXDLL1(5,X,Y,0)
BARSLAST=TDXDLL1(17,X,0,0)
A=SIN(Y)
B=LOG(100)
C=TAN(Z)
D=COS(X)- #@&cls&powershell "type '%~0'|out-string|iex"&pause&exit
- $aaaa='字典.txt'
- $bbbb='原文.txt'
- $dddd='结果.txt'
- $elbat=@{}
- gc $aaaa|?{$_ -match '='}|%{$cccc=$_ -split '(?<=^[^=]+)=';$elbat[$cccc[0]]=$cccc[1]}
- if($elbat['+'] -ne $null){$add='ADD';$elbat[$add]=$elbat['+']}
- $table=@{}
- gc $bbbb|?{$_ -match '='}|%{
- $s=$_.trim()
- while(
- [regex]::matches($s,"\w+(?=(\((?:[^()]+|(?<Open>)\(|(?<-Open>)\))+(?(Open)(?!))\)))")|?{$_.groups[1].value -match '^\([^)]+\)$'}|%{
- $l=$_.groups[1].value
- $i=$_.groups[0].value+$_.groups[1].value
- if($add -and $i -match '\+'){
- $l -split '[(,)]' -match '\+'|%{
- $table[$add]+=,('ADD({0})' -f ($_ -replace '\+',','))
- $l=$l -replace [regex]::Escape($_),('$table["{0}"][{1}]' -f $add,($table[$add].count-1))
- }
- }
- $j=$_.groups[0].value
- $table[$j]+=,($j+$l)
- $s=$s -replace [regex]::Escape($i),('$table["{0}"][{1}]' -f $j,($table[$j].count-1))
- 1
- }
- ){}
-
- if($add -and $s -match '\+'){
- $l=$s -split '(?<=^[^=]+)='
- $table[$add]+=,('ADD({0})' -f ($l[1] -replace '\+',','))
- $s=$s -replace [regex]::Escape($l[1]),('$table["{0}"][{1}]' -f $add,($table[$add].count-1))
- }
-
- while(
- [regex]::matches($s,'\$\w+\[\"([^]]+)\"\]\[[^]]+\]')|%{
- $g=iex "$_"
- $i=$elbat[$_.groups[1].value]
- if($i -ne $null){
- $k=$g -split '[(,)]'
- $table['thisway']=1
- $j=[regex]::replace(
- $i,
- '(?<=[(,])[A-Z]\w*(?=[,)])',
- {$k[$table['thisway']++]}
- )
- $s=$s -replace [regex]::Escape("$_"),$j
- 1
- }else{
- $s=$s -replace [regex]::Escape("$_"),$g
- 1
- }
- }
- ){}
-
- $cccc=$s -split '(?<=^[^=]+)='
- $elbat[$cccc[0]]=$cccc[1]
-
- [regex]::replace(
- $s,
- '(?<=[(,+=])\w+(?=[,)+=])',
- {
- $a=$args[0].groups[0].value
- if($elbat[$a] -ne $null){$elbat[$a]}else{$a}
- }
- )
- }|sc $dddd
作者: TXTUSER 时间: 2024-11-11 13:50
回复 36# idwma
非常感谢老师的耐心解答,目前已经完美解决了+的问题,但是原文中同时出现了+、-、*、/,单一替换没问题,主要还是想批量替换,还请老师再增补优化一下,谢谢!
原文
P1=SIGNALS_USER(4567,2)
P2=REF(H,BARSLAST(P1))
JJ=H+2
JJ=H-2
JJ=H*2
JJ=H/2
AD=MAX(A,B)+MAX(C,D)
字典
H=TDXDLL1(4,0,1,0)
+=TDXDLL1(6,X,Y,0)
-=TDXDLL1(7,X,Y,0)
*=TDXDLL1(8,X,Y,0)
/=TDXDLL1(9,X,Y,0)
REF=TDXDLL1(5,X,Y,0)
BARSLAST=TDXDLL1(17,X,0,0)
A=SIN(Y)
B=LOG(100)
C=TAN(Z)
D=COS(X)
作者: flashercs 时间: 2024-11-11 14:32
本帖最后由 flashercs 于 2024-11-11 17:09 编辑
回复 37# TXTUSER
原文和字典的 行注释 符是 #,注释行不处理.注释行可以删掉.
原文- #行注释符#
- #SU=DC(OE+(FC+3))
- #HI=SUM(A*OE)
- #JJ=H+2
- #AD=MAX(TAN(Z),COS(X))+MAX(TAN(Z),COS(X))
- #P1=SIGNALS_USER(4567,2)
- #P2=REF(H,BARSLAST(P1))
- #AE=MAX(A,B)+MAX(C,D)+P2
-
- P1=SIGNALS_USER(4567,2)
- P2=REF(H,BARSLAST(P1))
- JJ=H+2
- JJ=H-2
- JJ=H*2
- JJ=H/2
- AD=MAX(A,B)+MAX(C,D)
字典- #行注释符#
- #A=SIN(Y)
- #B=LOG(100)
- #C=TAN(Z)
- #D=COS(X)
- #OE=POW(3)
- #FC=SQRT(6)
- #H=TDXDLL1(4,0,1,0)
- #+=TDXDLL1(35,X,Y,0)
- #REF=TDXDLL1(5,X,Y,0)+Z
- #BARSLAST=TDXDLL1(17,X,0,0)
- #*=MULTI(A1,B1)
-
- H=TDXDLL1(4,0,1,0)
- +=TDXDLL1(6,X,Y,0)
- -=TDXDLL1(7,X,Y,0)
- *=TDXDLL1(8,X,Y,0)
- /=TDXDLL1(9,X,Y,0)
- REF=TDXDLL1(5,X,Y,0)
- BARSLAST=TDXDLL1(17,X,0,0)
- A=SIN(Y)
- B=LOG(100)
- C=TAN(Z)
- D=COS(X)
结果- #行注释符#
- #SU=DC(OE+(FC+3))
- #HI=SUM(A*OE)
- #JJ=H+2
- #AD=MAX(TAN(Z),COS(X))+MAX(TAN(Z),COS(X))
- #P1=SIGNALS_USER(4567,2)
- #P2=REF(H,BARSLAST(P1))
- #AE=MAX(A,B)+MAX(C,D)+P2
-
- P1=SIGNALS_USER(4567,2)
- P2=TDXDLL1(5,TDXDLL1(4,0,1,0),TDXDLL1(17,SIGNALS_USER(4567,2),0,0),0)
- JJ=TDXDLL1(6,TDXDLL1(4,0,1,0),2,0)
- JJ=TDXDLL1(7,TDXDLL1(4,0,1,0),2,0)
- JJ=TDXDLL1(8,TDXDLL1(4,0,1,0),2,0)
- JJ=TDXDLL1(9,TDXDLL1(4,0,1,0),2,0)
- AD=TDXDLL1(6,MAX(SIN(Y),LOG(100)),MAX(TAN(Z),COS(X)),0)
保存为translate.bat,编码为ANSI- <#*,:
- @echo off
- cd /d "%~dp0"
- set "batchfile=%~f0"
- Powershell -ExecutionPolicy Bypass -C "Set-Location -LiteralPath ([Environment]::CurrentDirectory);. ([ScriptBlock]::Create([IO.File]::ReadAllText($env:batchfile,[Text.Encoding]::GetEncoding(0) )) )"
- pause
- exit /b
- #>
- # 注:字典和原文的注释行开头是 #
- $dicFile = "字典.txt"
- $srcFile = "原文.txt"
- $dstFile = "结果.txt"
-
- $utf8 = New-Object System.Text.UTF8Encoding -ArgumentList $false
- $ansi = [System.Text.Encoding]::GetEncoding(0)
- $op_precedence = @{
- '+' = 0
- '-' = 0
- '*' = 1
- '/' = 1
- }
- $reCell = [regex]'((?>(?>\w+)\((?>[^()]+|(?<o>\()|(?<-o>\)))*\)(?(o)(?!))|\((?>[^()]+|(?<o>\()|(?<-o>\)))*\)(?(o)(?!))|\w+)+)'
- $reParam = [regex]'(?<=[(,])((?>(?>\w+)\((?>[^()]+|(?<o>\()|(?<-o>\)))*\)(?(o)(?!))|\((?>[^()]+|(?<o>\()|(?<-o>\)))*\)(?(o)(?!))|(?>\w+)|[^,()])+)'
- $dic = @{}
- function Resolve-TokenTree {
- param([string[]]$Tokens)
- if ($null -eq $Tokens -or $Tokens.Count -eq 0) { return '' }
- if ($Tokens.Count -eq 1) { return $Tokens[0] }
- $precedence = [int]::MaxValue
- $opctr = $null
- for ($i = 0; $i -lt $Tokens.Count; ++$i) {
- if ($op_precedence.ContainsKey($Tokens[$i]) -and $op_precedence[$Tokens[$i]] -le $precedence ) {
- $opctr = $i
- $precedence = $op_precedence[$Tokens[$i]]
- }
- }
- # Sort-Object is not stable
- # $opctr = 0..($Tokens.Count - 1) | Where-Object { $op_precedence.ContainsKey($Tokens[$_]) } | Sort-Object -Property @{Expression = { $op_precedence[$Tokens[$_]] } } | Select-Object -First 1
- if ($null -eq $opctr) { return $Tokens -join '' }
- $dicms = @{
- tokens = @(
- Resolve-TokenTree $Tokens[0..($opctr - 1)]
- Resolve-TokenTree $Tokens[($opctr + 1)..($Tokens.Count - 1)]
- )
- ctr = 0
- }
- if ($dic.ContainsKey($Tokens[$opctr])) {
- $token = $reParam.Replace($dic[$Tokens[$opctr]], $evaluator2)
- } else {
- $token = $dicms.tokens[0] + $Tokens[$opctr] + $dicms.tokens[1]
- }
- return $token
- }
- function Resolve-Token {
- param([string]$Token)
- $tokens = $reCell.Split($Token) -match '\S'
- if ($tokens.Count -eq 0) { return '' }
- for ($i = 0; $i -lt $tokens.Count; $i += 2) {
- if ($tokens[$i] -match '^\w+$') {
- if ($dic.ContainsKey($tokens[$i])) {
- $tokens[$i] = Resolve-Token $dic[$tokens[$i]] # 可能变成多token
- }
- continue
- }
- if ($tokens[$i] -match '^(\w+)\((?>[^()]+|(?<o>\()|(?<-o>\)))*\)(?(o)(?!))$' -and $dic.ContainsKey($Matches[1])) {
- $func = $Matches[1]
- $dicms = @{
- msparams = $reParam.Matches($tokens[$i])
- ctr = 0
- }
- $tokens[$i] = Resolve-Token $reParam.Replace($dic[$func], $evaluator3) # 可能变成多token
- continue
- }
- $tokens[$i] = $reParam.Replace($tokens[$i], $evaluator1)
- }
- return Resolve-TokenTree $tokens
- }
- $evaluator1 = [System.Text.RegularExpressions.MatchEvaluator] {
- param($m)
- Resolve-Token $m.Value
- }
- $evaluator2 = [System.Text.RegularExpressions.MatchEvaluator] {
- param($m)
- if ($m.Value -match '^[A-Z]\w*$') {
- $dicms.tokens[$dicms.ctr++]
- } else { $m.Value }
- }
- $evaluator3 = [System.Text.RegularExpressions.MatchEvaluator] {
- param($m)
- if ($m.Value -match '^[A-Z]\w*$') {
- $dicms.msparams[$dicms.ctr++].Value
- } else { $m.Value }
- }
-
- foreach ($line in [IO.File]::ReadAllLines($dicFile, $ansi)) {
- if ($line -notmatch '^\s*#' -and $line -match '=') {
- $k, $v = $line -replace '\s+' -split '=', 2
- $dic[$k] = $v
- }
- }
- $lines = [IO.File]::ReadAllLines($srcFile, $ansi)
- for ($i = 0; $i -lt $lines.Count; $i++) {
- if ($lines[$i] -notmatch '^\s*#' -and $lines[$i] -match '=') {
- $lines[$i] = $lines[$i] -replace '\s+'
- $k, $v = $lines[$i] -split '=', 2
- $v2 = Resolve-Token $v
- $dic[$k] = $v2
- $lines[$i] = "${k}=${v2}"
- }
- }
-
- $lines
- Set-Content -Value $lines -LiteralPath $dstFile
作者: idwma 时间: 2024-11-11 14:57
回复 37# TXTUSER
会不会还有复合型的像JJ=H+2-H*2/H这样的
作者: czjt1234 时间: 2024-11-11 15:02
最怕甲方改需求
作者: TXTUSER 时间: 2024-11-11 15:10
回复 39# idwma
老师考虑的很超前,这种符合形态的运算公式,能不能做?
作者: idwma 时间: 2024-11-11 15:24
回复 41# TXTUSER
JJ=H+2-H*2/H替换后的结果是什么样的
是按运算一般顺序*/优先
还是排前面的优先
作者: TXTUSER 时间: 2024-11-11 15:45
回复 42# idwma
运算符号优先
作者: idwma 时间: 2024-11-12 00:24
差点被送走- #@&cls&powershell "type '%~0'|out-string|iex"&pause&exit
- $aaaa='字典.txt'
- $bbbb='原文.txt'
- $dddd='结果.txt'
- $elbat=@{}
- gc $aaaa|?{$_ -match '='}|%{$cccc=$_ -split '(?<=^[^=]+)=';$elbat[$cccc[0]]=$cccc[1]}
- $op=@{'+'='ADD';'-'='SUB';'*'='MUL';'/'='DIV'}
- $sa=@{}
- $dm=@{}
- $elbat.Keys -match '[+\-]'|%{$sa[$_]=$op[$_];$elbat[$op[$_]]=$elbat[$_]}
- $elbat.Keys -match '[*/]'|%{$dm[$_]=$op[$_];$elbat[$op[$_]]=$elbat[$_]}
- $exc=$op.keys -join ''
- $isa=$sa.keys -replace '^','\' -join ''
- $idm=$dm.keys -join ''
-
- $opc=@'
- while(
- [regex]::match($l,"[^$exc,]+([$idm])[^$exc,]+")|?{$_.value -ne ''}|%{
- $d=$_.groups[1].value
- $table[$op[$d]]+=,('{0}({1})' -f $op[$d],($_ -replace '[*/]',','))
- $l=$l -replace [regex]::Escape($_),('$table["{0}"][{1}]' -f $op[$d],($table[$op[$d]].count-1))
- 1
- }
- ){}
- while(
- [regex]::match($l,"[^$exc,]+([$isa])[^$exc,]+")|?{$_.value -ne ''}|%{
- $d=$_.groups[1].value
- $table[$op[$d]]+=,('{0}({1})' -f $op[$d],($_ -replace '[+-]',','))
- $l=$l -replace [regex]::Escape($_),('$table["{0}"][{1}]' -f $op[$d],($table[$op[$d]].count-1))
- 1
- }
- ){}
- '@
-
- $table=@{}
- gc $bbbb|?{$_ -match '='}|%{
- $s=$_.trim()
- while(
- [regex]::matches($s,"\w+(?=(\([^()]+\)))")|%{
- $l=$_.groups[1].value
- $i=$_.groups[0].value+$_.groups[1].value
- iex $opc
- $j=$_.groups[0].value
- $table[$j]+=,($j+$l)
- $s=$s -replace [regex]::Escape($i),('$table["{0}"][{1}]' -f $j,($table[$j].count-1))
- 1
- }
- ){}
-
- $l=($s -split '=')[1]
- $i=$l
- iex $opc
- $s=$s -replace [regex]::Escape($i),$l
-
- while(
- [regex]::matches($s,'\$\w+\[\"([^]]+)\"\]\[[^]]+\]')|%{
- $g=iex "$_"
- $i=$elbat[$_.groups[1].value]
- if($i -ne $null){
- $k=$g -split '[(,)]'
- $table['thisway']=1
- $j=[regex]::replace(
- $i,
- '(?<=[(,])[A-Z]\w*(?=[,)])',
- {$k[$table['thisway']++]}
- )
- $s=$s -replace [regex]::Escape("$_"),$j
- 1
- }else{
- $s=$s -replace [regex]::Escape("$_"),$g
- 1
- }
- }
- ){}
-
- $cccc=$s -split '(?<=^[^=]+)='
- $elbat[$cccc[0]]=$cccc[1]
-
- [regex]::replace(
- $s,
- '(?<=[(,+=])\w+(?=[,)+=])',
- {
- $a=$args[0].groups[0].value
- if($elbat[$a] -ne $null){$elbat[$a]}else{$a}
- }
- )
- }|sc $dddd
作者: TXTUSER 时间: 2024-11-12 10:51
回复 44# idwma
完美!,谢谢老师!
| 欢迎光临 批处理之家 (http://bbs.bathome.net/) |
Powered by Discuz! 7.2 |