回复 3# Five66
这个命令的作用是删除重复行,出自于大名鼎鼎的sed1line
http://www.pement.org/sed/sed1line.txt
中文版的解释
http://bbs.chinaunix.net/thread-306867-3-1.html#pid2031834
英文版的解释
https://catonmat.net/sed-one-liners-explained-part-three
使用[[:print:]]取代[ -~]可以解决某些环境下未能删除重复行的问题
https://stackoverflow.com/questions/5930246/what-does-this-sed-expression-from-todo-sh-do
Linux:- sed -n 'G; s/\n/&&/; /^\([[:print:]]*\n\).*\n\1/d; s/\n//; h; P' 1.txt
Windows:- sed -n "G; s/\n/&&/; /^\([[:print:]]*\n\).*\n\1/d; s/\n//; h; P" 1.txt
首先搞清楚几个基本命令的作用:
G Append hold space to pattern space.
d Delete pattern space. Start next cycle.
h Copy pattern space to hold space.
P Print up to the first embedded newline of the current pattern space.
然后使用 sedsed 执行一下观察详细过程:
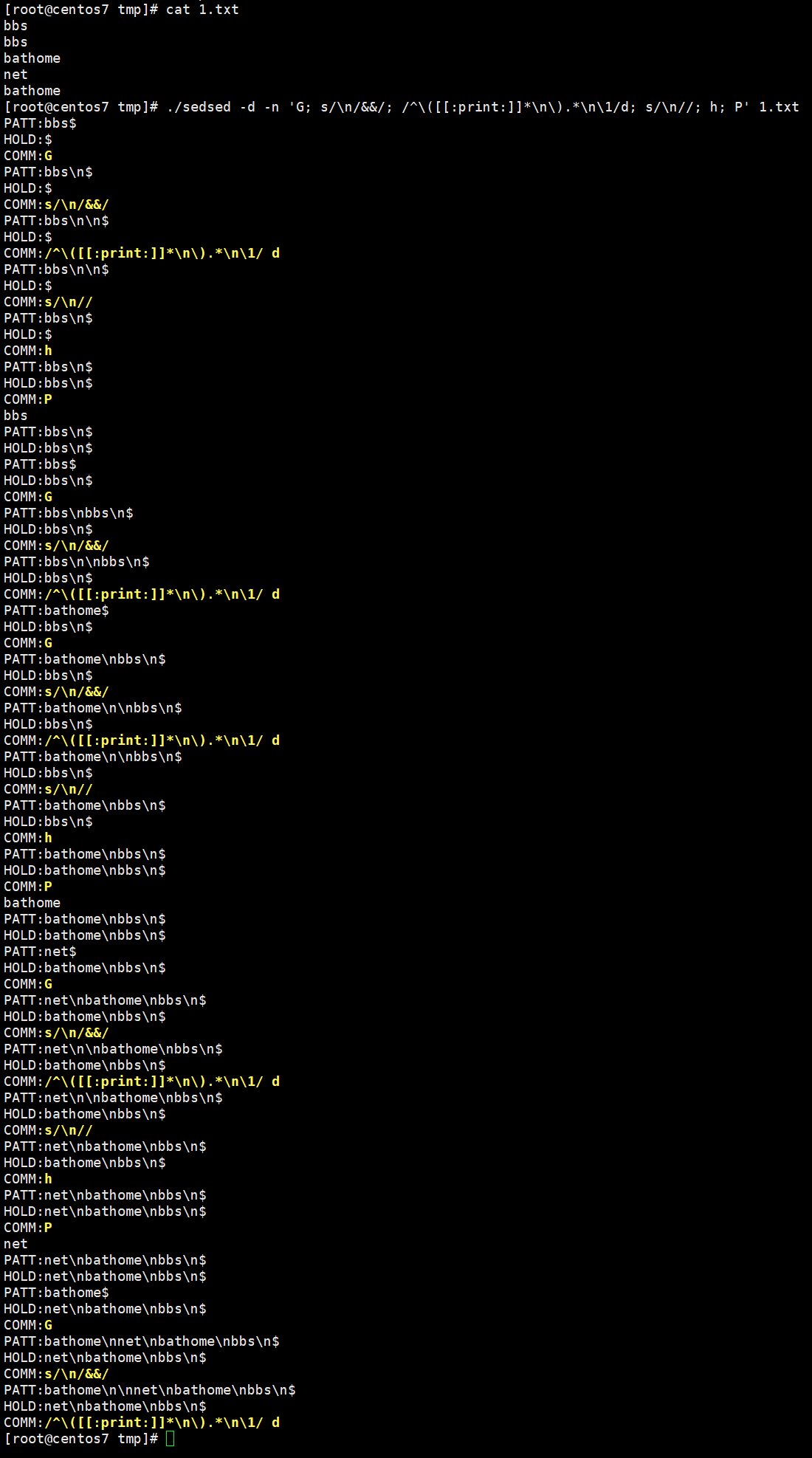
批处理BAT脚本如何删除文本文件中重复的行
http://bbs.bathome.net/thread-5219-1-1.html
http://bbs.bathome.net/thread-5509-1-1.html
http://bbs.bathome.net/thread-4690-1-1.html
http://bbs.bathome.net/thread-5326-1-1.html
http://bbs.bathome.net/thread-4896-1-1.html | 

 发表于 2023-9-6 16:21
|
发表于 2023-9-6 16:21
|